Modulith architecture is the new buzzword. We see new frameworks cropping up that seek to implement this architecture. We have always been strong propounders of a modular Architecture. We implement these principles in Chenile. To us, Monolith is a state of mind. If we write code that is modular then we don’t need a deployment architecture to mirror this modularity. Please see the autonomy pyramid. I am going to call the traditional approach to writing micro services as a micro deployment architecture - where each service has its own deployment. I am going to see if I can convince you that micro deployment architecture is wasteful for the most part.
Micro deployments complicate things - especially for small companies. Surprisingly enough, even bigger enterprises don’t often need micro deployments. The scalability must be really massive to justify this complexity. If Amazon Prime can go back to a more monolithic architecture, what is your excuse? If you outgrow this, it is a good problem to have. Chenile will support such micro deployment architectures. It just does not recommend them by default.
The upside/downside to micro deployments
We believe that there are a few problems that make micro deployments untenable for the most part. In the process of outlying the problems we will also combat some of the popular arguments that have traditionally been advanced to justify a micro deployment architecture.
Scalability
One of the reasons that is traditionally advanced is that micro service deployments allow independent scalability on a micro services level. You can scale X service independent of Y service. Let me break this news to you. We don’t need independent scalability on a micro services level. We may need some independent scalability on a “category” of services. Not on service to service level. If I decide to scale the user service, I automatically need to scale the services that it depends on! In a micro services deployment, it is not immediately obvious as to what other services are being called by the User service. So the scalability may be skewed. We may scale User Service and not scale the Role service sufficiently thereby leading to problems which may take a few days to detect. In fact, most organizations that I worked for classify services into categories and apply the same scalability parameters (like auto scaling, availability etc.) to each category of service. If you are going to apply the same parameters, you might as well make them part of the same monolith.
Ducks in a row problem
One of the chief complaints about deploying a monolith is that all ducks need to be lined up in a row. All the service teams need to be ready for testing the deployment. This claim is true to an extent. Indeed, there is an inherent risk in deployment. But this can be mitigated to a large extent by “Shifting Left”. Unit testing must not merely test the service. It should test the deployed service using HTTP and similar transports so that the actual request during runtime is simulated. In many teams, people don’t invest enough on unit tests. Even if they do so, they do not test the deployed code they test merely a single class or a small bunch of classes. If the Unit tests cover HTTP requests then this problem goes away for the most part. Also, we are not advocating that the entire enterprise must be one giant monolith. We are merely stating that we combine a few services to form a “mini monolith”.
Deployment (& Observability) Proliferation
One of the biggest downsides of a micro deployment architecture is that there are too many deployments that would happen. This considerably hinders observability and hugely inflates infrastructure needs. Since deployments get transferred to individual teams we will also have a problem with skill mismatch. Developers start dabbling as deployment architects and don’t enforce one deployment stereotype. Java is configured slightly differently with different options and versions. Auto scalability is configred differently. Sometimes different Linux versions are used. This makes it hard to enforce consistency. I have been involved in projects whose only aim was to standardize the deployment stack to minimize costs. By minimizing on the number of deployments, we can dedicate a group of services to one deployment team which can then standardize deployment templates and can write meaningful deployment and monitoring scripts to ensure automation. They can also invest in AI tools for auto-detection of errors, restarting servers, health checks etc.
Tech Stack Version Dissonance
We have heard people stating that if there are multiple services residing in one monolith, then their services cannot use different versions of tech stacks from open source such as Spring, Apache commons etc. If that is a claim you are making then congratulations! You have succeeded in making a good thing look bad! It is vital to use the same versions of common libraries. It is important to upgrade your software constantly to avoid possible vulnerabilities emanating form old versions of the software. Monoliths force you to do that which is a good thing.
Leveraging Company wide Common Libraries
This topic is related to the previous one. Within the same company, people write libraries for common functionality. In the micro deployments world, people try to clone these libraries or write their own versions of these libraries instead of reusing what is available. Monolithic architectures force teams to upgrade to new versions of these libraries. Library management is an important part of enforcing a common architecture.
Flexibility in deploying Services
One other claim is freeze periods are different for different countries. For example, Diwali is a freeze period for companies based out of India whilst the Holiday season is the freeze period for much of the US and Europe. During freeze periods monoliths can cause problems since the US deployment is tied to Indian deployment. Hence we need to separate the deployments. This argument is valid for separating deployments between different regions. It still does not mandate that each service will need its own deployment.
Recommendations
Now that we busted some of the myths about the perceived virtues of a micro deployment architeture, let us make some recommendations.
Separate Deployment from Development
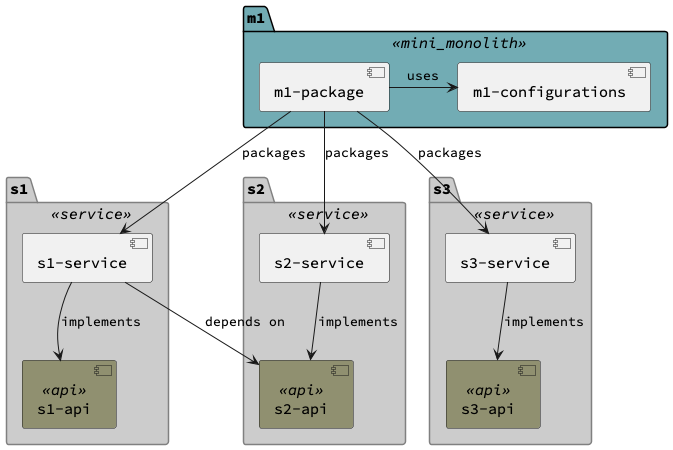
We should use different code modules for deployment and development. The deployment modules are called “mini monoliths” and are packaged in two modules in Chenile (they end in -package (for code) and -configuration (for configurations) ). Mini Monoliths bring together multiple services - each residing in their own code modules. The package code module is not aware of what it is packaging. (except for the POM file where it calls out all the service code modules). The configuration code module supplies all the requisite configurations for all the service modules in one place.
The service code modules are autonomous. They dont make any assumptions about their dependencies and their deployments. They are dependent on configurations at the common configurations module of the mini monolith. Otherwise they are unaware of everything else.
This separation is vital for the modulith architecture to work. See the recommended code module structure below:
Shift testing to the left
Testing must be comprehensive at the code development stage. It should be against the packaged code - not just for individual service classes. The entire packaged code should be deployed and tested in the same test case. This ensures that besides testing for the service class, we also test for serialization, de-serialization, horizontal concerns etc. Testing can be against mocks. Mocks must be created for every service keeping in mind CDC (Consumer Driven Contracts) approach. Creating CDC mocks become important to enforce that testing could be carried out without needing the actual service.
Splitting the Monolith into Mini Monoliths
Even with the above two recommendations taken care of, it is important to make sure that the monolith does not become unwieldy. We will need to break it into multiple mini monoliths. In this way, cohesive teams with the same scalability requirements come together whilst teams that are not so cohesive stay separate. It should be remembered that there should be a dedicated SRE (System Reliability Engineering) professional or team dedicated for the upkeep of every mini monolith.
Consistent Governance
Governance is a very important part. The Governance must be enforced by a virtual team of people. For example, the mini monolith SRE teams come together at the company level to ensure that there is consistent governance in the upkeep of deployments. Architects must come together to ensure that development is done consistently. A Parent pom that lists out all the external dependencies is an important part of Governance. Chenile provides such a POM. (which in turn is derived from Spring Boot pom)
In Conclusion
By following these recommendations we ensure complete autonomy in testing and development. We can create a functioning modulith architecture for the entire enterprise.