Motivation
Micro services have become the prevalent paradigm for development. We could create autonomous teams with segmented responsibilities. Each team knows its respective domain and builds services in them. All the teams collaborate to create an ecosystem that can accomplish complex tasks with aplomb.
In our experience of working for over three decades in application development with companies of all sizes, we have observed the Autonomy pyramid in action. We discuss this below. We also discuss our recommendations.
Autonomy & Cohesion
De-coupling is an important Agile mantra. Afterall, the essence of Agile development is the concept of strong self-organizing teams. Self-organizing teams need a lot of autonomy. They need to be able to function like mini enterprises in their own right.
Domain Driven Design (DDD) divides the functionality of a complex ecosystem into Bounded Contexts (BC). We need to think about companies - from large enterprises to startups - as comprising of smaller autonomous companies with each one of these responsible for a bounded context. Each bounded context(BC) has clearly defined contracts that it exposes to other bounded contexts within the enterprise. In fact it is possible that the same BC can function autonomously across enterprises. For example think about AWS. What was an erstwhile Amazon Bounded context, has become a global one that others can reuse. Hence each bounded context has the potential to spawn into a new company. And autonomy makes this possible!
However, there are two important overarching principles that need to be imposed over these Agile self-organizing autonomous teams:
- Cohesion: The bounded contexts must come together to assemble an ecosystem. We are not building a set of dissonant companies. We are building an ecosystem that functions as a cohesive whole to accomplish a stated functionality. This means that these bounded contexts need to come together with published contracts, model objects, Data Transfer Objects (DTO) etc. so that others can consume these contracts to accomplish the bigger objective.
- Governance: There are certain concerns that need to come together in an ecosystem. We want to leverage economy of scale when we build a bigger company. We want fungibility - the ability to move people from one org to another within the company. We want certain architectural principles to be leveraged across the company. We also want to leverage common infrastructure and services throughout.
So it is a delicate balance - between autonomy on one side and cohesion/governance on the other. We want a framework and development platform that caters to these dual (but conflicting) concerns. How do we make sure that a bounded context is given the requisite autonomy without compromising the overall cohesion that is required to build a stable and sustainable ecosystem?
The Autonomy Py ramid
The pyramid shown below illustrates this dichotomy between the two conflicting forces of autonomy and governance/cohesion.
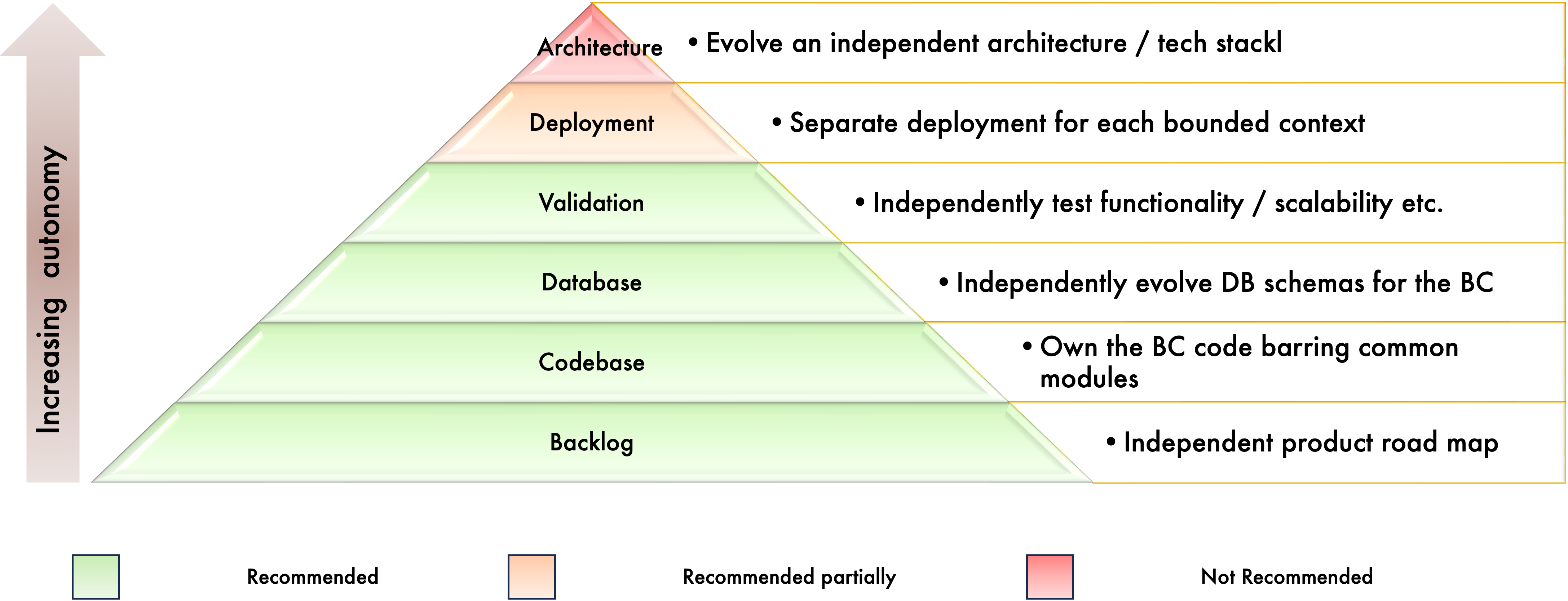
Lower layers in the pyramid are absolutely required to build the edifice on which the other layers can be built. As we see, the greater the concerns that are independent, the more autonomous the bounded contexts become! But greater autonomy also decreases cohesion and the potential for reuse. It will tip the pyramid in favor of chaos and dissonance. We advocate a good amount of autonomy so that teams become productive but discourage the type of autonomy that decreases governance/cohesion. Our recommendations and reasons are tabulated below:
| S. No. | Feature | Do we favor this? | Justification | How does Chenile help? |
|---|---|---|---|---|
| 1 | Backlog | Yes | A healthy independent backlog is vital for autonomy | Chenile helps in building features independently. |
| 2 | Codebase | Yes | Code must be modular and autonomous. Yet it must expose the correct interfaces for others to consume | Chenile generator generates code that complies to Dependency Inversion Principle. Services can be independent but they expose an API that publishes the contracts/model objects. |
| 3 | Database | Yes | Databases must evolve independently. But it should be possible to expose views that stitch across bounded contexts. | Chenile recommends the CQRS(Command Query Responsibility Separation) pattern to separate commands and queries. Chenile ships with a query tool that provides views without needing model objects. |
| 4 | Validation | Yes | It should be possible to validate code independent of other groups. Otherwise the testing becomes too fragile and dependent on multiple groups. | Chenile generates an entire test harness based on Spring MVC and Cucumber for BDD. It allows teams to shift left for testing and validation. |
| 5 | Deployment | To an extent | Deployment autonomy is often overhyped. It causes more harm than good. It proliferates infrastructure and observability needs. | Chenile advocates the Mini Monolith pattern. Chenile recommends that teams pack together a bunch of services and deploy them together instead of making every microservice a full-fledged deployment |
| 6 | Architecture / Tech Stack | No | Architectural and Tech Stack divergence increases complexity and decreases the ability to standardize and reuse software. | Chenile provides common libraries and tech stack standardization by having a common Maven POM. Experimentation must be done by architectural teams with the ultimate objective of developing a blue print that the entire company can leverage. |
In the following sections, we discuss these recommendations in more detail.
Architectural / Tech Stack Standardization
Chenile recommends that we have limited tech stacks with common architectural patterns. This vastly improves resource fungibility besides promoting reuse. Naming conventions further help in easily identifying the usage of these patterns in the org. This allows us to write utilities/ libraries that exploit this commonality thereby fostering greater reuse.
All Chenile services must be written as independent maven modules that are brought together in a package. These services will leverage a common parent pom which in turn inherits from (chenile-parent) which lastly inherits from the spring boot parent pom. Thus the entire tech stack is standardized and specified in one place. The correct versions must be defined at the parent pom level and not at the service level.
Chenile also standardizes the architecture by recommending specific architectural blue prints. Please look at the design patternsfor more information. The framework itself leverages certain patterns like chain of responsibility which is advocated to be practised for all services. (for example see the section on last mile interception.
Deployment Strategy - Mini Monoliths
Chenile introduces the concept of a mini monolith. A mini monolith can also be called as a modulith in compliance to the modulith pattern that is becoming increasingly famous these days. A chenile mini monolith is a package that deploys one or more modular services. It takes the jars from a bunch of services and deploys them together. All the code required for executing the services is packaged in the mini monolith. The mini monolith itself is unaware of the individual services that it is packaging. The only place it knows about them is in its POM file where it includes the services as dependencies.
A mini monolith can be dockerized and deployed as a container. These containers can be executed using a container management deployment framework such as Kubernetes. Alternately these containers can be deployed in individual machines (both real and virtual). Mini monoliths contain code and configuration. These interact with other mini monoliths in the ecosystem to accomplish the overall functionality. The mini monoliths may rely on additional resources such as databases, caches, service registries, API gateways, Kafka (or similar) brokers etc.
Chenile Service Registry
Chenile service registry provides a place to store the metadata about a service. Chenile relies on this metadata to construct a runtime proxy that implements the service contracts. This allows the developers to access a service using its interface irrespective of where it is deployed.
Separating Development from Deployment
Chenile strongly advocates that development must be de-coupled from deployment. This means that the developers don’t upfront assume where the service (or its dependencies) is running. It relies on Java contracts to talk to its dependencies using the Chenile proxy framework which in turn relies on the Chenile service registry.
For instance, if service1 needs to call service2, it should not assume where service2 is running. It might be running locally in the same VM or it might be running remotely in another VM. Hence a service2 proxy is required to access service2 using the chenile proxy framework.
Validation Strategy - BDD, Cucumber, Spring MVC etc.
Chenile services must be developed to be independently testable. Testable units include the entire HTTP harness - not just the service. It would include all the Chenile interceptors that would be called before the service itself is called. We should write code that can be tested via HTTP not just using simple beans as is usually done in traditional JUnits. This means that we need to integrate Spring containers, H2 database for mocking databases, Spring MVC for testing web based invocations, Cucumber to write BDD features, Liquibase to create the database schema and populate this will initial data etc. Spring Boot provides this entire infrastructure and Chenile leverages this in its code generator. Chenile generated services are tested using BDD with Cucumber in a special Gherkin language that we developed for Chenile.
Chenile recommends Behavior Driven Development (BDD) so that developers can validate their test cases with their business analysts. See this section for more details
Chenile is compatible with Consumer Driven Contracts (CDC) as well. CDC eliminates the need for different mocks existing for the same service in different consumers test code. There are plans to integrate CDC more tightly with Chenile.
Database Schema - Command & Query Databases
In the micro services world, the data is split between different databases - each one belonging to different bounded contexts. Typically, each bounded context will have its own database. This works well for commands which are responsible to create, update and delete data in the bounded context.
However, queries will require data that spans across different databases. This results in the much dreaded “n+1” selects problem which poses a big problem for scalability. Chenile recommends that we split the command and query responsibilities in accordance with the CQRS pattern (Command Query Responsibility Separation). We recommend different frameworks for Command and Query. For command, we can use a standard ORM such as JPA or Hibernate. For query, we recommend a simple mapping framework such as Mybatis. We will discuss these patterns in other pages.
Chenile leverages spring integrations with JPA and Mybatis in its code generators.
Code Separation
To keep code modular, Chenile recommends a multi-module Maven POM with different code modules as discussed below.
A note on Code Modules
Code Modules show themselves as projects in the IDE such as Eclipse or IntelliJ. Each code module is responsible to generate one JAR file. The build process produces the JAR file from the code module code.
In Chenile any service is split between two code modules called API module and the service module. For example, service1 is split into two code modules - service1-api and service1-service. API contains only contracts that are exposed by service1. The service module contains the implementation of the contracts defined in service1-api. If service1 depends on service2 then the dependency is reflected as service1-service depending on service2-api. Since there is no dependency between service1-service and service2-service, it is not possible to write code that depends on how service2 is implemented. This keeps it clean and modular.
Code Modules & Testing
Since the services are generated in independent code modules, it is possible to test them independently as well. In ther example above, since service1-service only depends on service2-api and not on service2-service, the testing of service1 is independent of the testing on service2. In rare cases, it is possible that we might want to have a dependency service1-service -> service2-service in scope = ‘test’. That approach is recommended only for highly cohesive services. Otherwise, it is best to mock service2 in testing service1.
Further, there must be a distinction between Non functional requirements (NFR) and functionality. Functionality - such as User management , Order management etc. must be owned by different bounded contexts. But there must be other bounded contexts that are responsible for horizontal concerns such as logging, auditing etc. Typically, these bounded contexts are owned by horizontal teams such as Architecture team, performance team etc. NFRs are also implemented in a common way using Chenile interceptors that can then be integrated with the code execution pipeline. (see this section on last mile interception. )
Thus Chenile with its code generation capabilities and its blue prints, provides a solid edifice to write Micro services.